Introduction to Computer Vision Concepts
Introduction
- Computer Vision is one of the core areas of AI.
- It focuses on creating solutions that enable AI application to see the world and make sense of it.
- The ability of computers to process images is the key to creating software that can emulate human visual perception.
Overview
- Computer vision capabilities can be categorized into a few main types:
| Type | Description |
|---|---|
| Image analysis | The ability to detect, classify, caption, and generate insights. |
| Spatial analysis | The ability to understand people's presence and movements within physical areas in real time. |
| Facial recognition | The ability to recognize and verify human identity. |
| Optical character recognition (OCR) | The ability to extract printed and handwritten text from images with varied languages and writing styles. |
- Before we can explore image processing and other computer vision capabilities, its useful to consider what an image actually is in the context of data for a computer program.
Images as pixel arrays
- To a computer, an image is an array of numeric pixel values. For example, consider the following array:
0 0 0 0 0 0 0
0 0 0 0 0 0 0
0 0 255 255 255 0 0
0 0 255 255 255 0 0
0 0 255 255 255 0 0
0 0 0 0 0 0 0
0 0 0 0 0 0 0
- The array consists of seven rows and seven columns, representing the pixel values for a 7x7 pixel image (which is known as the image's resolution).
- Each pixel has a value between 0 (black) and 255 (white); with values between these bounds representing shades of gray.
- The image represented by this array looks similar to the following (magnified) image:

- The array of pixel values for this image is two-dimensional (representing rows and columns, or x and y coordinates) and defines a single rectangle of pixel values.
- A single layer of pixel values like this represents a grayscale image.
- In reality, most digital images are multidimensional and consist of three layers (known as channels) that represent red, green, and blue (RGB) color hues.
- For example, we could represent a color image by defining three channels of pixel values that create the same square shape as the previous grayscale example:
Red:
150 150 150 150 150 150 150
150 150 150 150 150 150 150
150 150 255 255 255 150 150
150 150 255 255 255 150 150
150 150 255 255 255 150 150
150 150 150 150 150 150 150
150 150 150 150 150 150 150
Green:
0 0 0 0 0 0 0
0 0 0 0 0 0 0
0 0 255 255 255 0 0
0 0 255 255 255 0 0
0 0 255 255 255 0 0
0 0 0 0 0 0 0
0 0 0 0 0 0 0
Blue:
255 255 255 255 255 255 255
255 255 255 255 255 255 255
255 255 0 0 0 255 255
255 255 0 0 0 255 255
255 255 0 0 0 255 255
255 255 255 255 255 255 255
255 255 255 255 255 255 255
- Here's the resulting image:

- The purple squares are represented by the combination:
Red: 150
Green: 0
Blue: 255
- The yellow squares in the center are represented by the combination:
Red: 255
Green: 255
Blue: 0
Understand image processing
- A common way to perform image processing tasks is to apply filters that modify the pixel values of the image to create a visual effect.
- A filter is defined by one or more arrays of pixel values, called filter kernels.
- For example, you could define filter with a 3x3 kernel as shown in this example:
-1 -1 -1
-1 8 -1
-1 -1 -1
-
The kernel is then convolved across the image, calculating a weighted sum for each 3x3 patch of pixels and assigning the result to a new image.
-
It's easier to understand how the filtering works by exploring a step-by-step example.
-
Let's start with the grayscale image we explored previously:
0 0 0 0 0 0 0
0 0 0 0 0 0 0
0 0 255 255 255 0 0
0 0 255 255 255 0 0
0 0 255 255 255 0 0
0 0 0 0 0 0 0
0 0 0 0 0 0 0
- First, we apply the filter kernel to the top left patch of the image, multiplying each pixel value by the corresponding weight value in the kernel and adding the results:
(0 x -1) + (0 x -1) + (0 x -1) +
(0 x -1) + (0 x 8) + (0 x -1) +
(0 x -1) + (0 x -1) + (255 x -1) = -255
- The result (-255) becomes the first value in a new array.
- Then we move the filter kernel along one pixel to the right and repeat the operation:
(0 x -1) + (0 x -1) + (0 x -1) +
(0 x -1) + (0 x 8) + (0 x -1) +
(0 x -1) + (255 x -1) + (255 x -1) = -510
- Again, the result is added to the new array, which now contains two values:
-255 -510
- The process is repeated until the filter has been convolved across the entire image, as shown in this animation:

- The filter is convolved across the image, calculating a new array of values.
- Some of the values might be outside of the 0 to 255 pixel value range, so the values are adjusted to fit into that range.
- Because of the shape of the filter, the outside edge of pixels is not calculated, so a padding value (usually 0) is applied.
- The resulting array represents a new image in which the filter has transformed the original image.
- In this case, the filter has had the effect of highlighting the edges of shapes in the image.
| Original Image | Filtered Image |
|---|---|
 |  |
- Because the filter is convolved across the image, this kind of image manipulation is often referred to as convolutional filtering.
- The filter used in this example is a particular type of filter, called a laplace filter, that highlights the edges on objects in an image.
- There are many other kinds of filter that you can use to create blurring, sharpening, color inversion, and other effects.
Machine learning for computer vision
- The ability to use filters to apply effects to images is useful in image processing tasks, such as you might perform with image editing software.
- However, the goal of computer vision is often to extract meaning, or at least actionable insights, from images; which requires the creation of machine learning models that are trained to recognize features based on large volumes of existing images.
Convolutional neural networks (CNNs)
-
One of the most common ML model architectures for computer vision is a convolutional neural network (CNN), a type of deep learning architecture.
-
CNNs apply filters to images to get numeric feature maps.
-
Then, they feed the feature values into a deep learning model to generate label prediction.
-
In an image classification scenario, the label represents the main subject of the image, that is, what is this image of.
-
During the training process for a CNN, filter kernels are initially defined using randomly generated weight values.
-
Then, as the training process progresses, the models predictions are evaluated against known label values, and the filter weights are adjusted to improve accuracy.
-
Eventually, the trained fruit image classification model uses the filter weights that best extract features that help identify different kinds of fruit.
-
The following diagram illustrates how a CNN for an image classification model works:
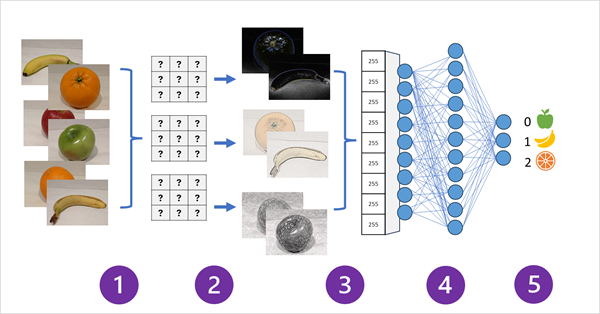
Step 1:
- Images with known labels (for example, 0: apple, 1: banana, or 2: orange) are fed into the network to train the model.
Step 2:
- One or more layers of filters is used to extract features from each image as it is fed through the network.
- The filter kernels start with randomly assigned weights and generate arrays of numeric values called feature maps.
Step 3:
- The feature maps are flattened into a single dimensional array of feature values.
Step 4:
- The feature values are fed into a fully connected neural network.
Step 5:
-
The output layer of the neural network uses a softmax or similar function to produce a result that contains a probability value for each possible class, for example [0.2, 0.5, 0.3].
-
During training the output probabilities are compared to the actual class label - for example, an image of a banana (class 1) should have the value [0.0, 1.0, 0.0].
-
The difference between the predicted and actual class scores is used to calculate the loss in the model.
-
Then the weights in the fully connected neural network and the filter kernels in the feature extraction layers are modified to reduce the loss.
-
The training process repeats over multiple epochs until an optimal set of weights has been learned.
-
Then, the weights are saved and the model can be used to predict labels for new images for which the label is unknown.
- CNN architectures usually include multiple convolutional filter layers and additional layers to reduce the size of feature maps, constrain the extracted values, and otherwise manipulate the feature values.
- These layers have been omitted in this simplified example to focus on the key concept, which is that filters are used to extract numeric features from images, which are then used in a neural network to predict image labels.
Understand modern vision models
- CNNs have been at the core of computer vision solutions for many years.
- Although they are commonly used to solve image classification problem, that is identifying what image contains, they are also the basis for more complex computer vision models.
- For example, object detection models combine CNN's feature extraction layers with the identification of regions of interest in images to locate multiple classes of object in the same image.
Transformers
-
Most advances in computer vision over the decades have been driven by improvements in CNN-based models.
-
However, in NLP, a type of Neural Network architecture, called a Transformer, has enabled the development of sophisticated models for languages.
-
Transformers work by processing huge volumes of data, and encoding language tokens.
-
Embedding representing a set of dimensions that each represent some semantic attribute of the token.
-
The embeddings are created such that tokens that are commonly used in the same context define vectors that are more closely aligned than unrelated words.
-
As a simple example, the following diagram shows some words encoded as three-dimensional vectors, and plotted in a 3D space:
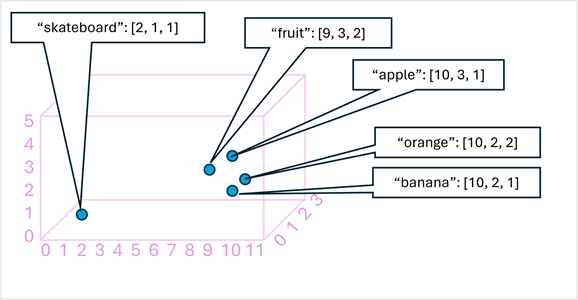
- Tokens that are semantically similar are encoded in similar directions, creating a semantic language model.
- This makes it possible to build sophisticated NLP solutions for text analysis, translation, language generation, and other tasks.
- We have used only three dimensions, because that's easy to visualize.
- In reality, encoders in transformer networks create vectors with many more dimensions, defining complex semantic relationships between tokens based on linear algebraic calculations.
- The math involved is complex, as is the architecture of a transformer model.
- Our goal here is just to provide a conceptual understanding of how encoding creates a model that encapsulates relationships between entities.
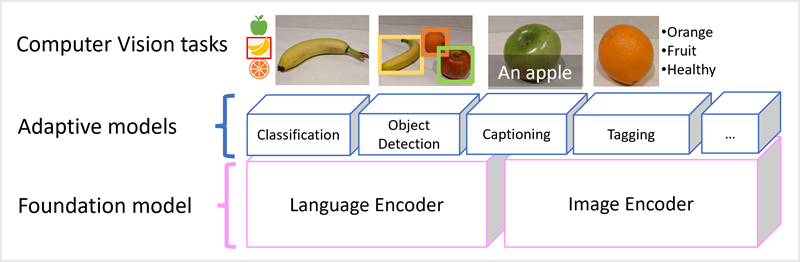
Multi-modal models
- After the success of transformers as a way to build language models, AI researchers started thinking of the same approach can be effective for image data.
- The result is the development of multi-modal models.
- Multi-modal model is trained using large volumes of captioned images, with no fixed labels.
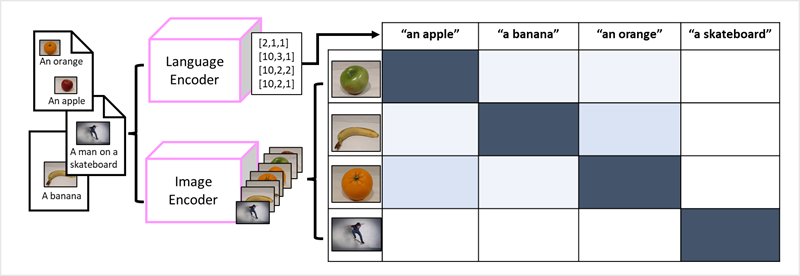
- An image encoder extracts features from images based on pixel values and combines tTagging visual featureshem with text embeddings created by a language encoder.
- The overall model encapsulates relationships between natural language token embeddings and image features, as shown here:
- The Microsoft Florence model is such a model.
- It is trained with huge volumes of captioned images from the Internet.
- It includes both a language encoder and an image encoder.
- It is an example of a foundation model.
- In other words, a pre-trained general model on which you can build multiple adaptive models for specialist tasks.
- For example, you can use Florence as a foundation model for adaptive models that perform:
- Image classification: Identifying to which category an image belongs.
- Object detection: Locating individual objects within an image.
- Captioning: Generating appropriate descriptions of images.
- Tagging: Compiling a list of relevant text tags for an image.